
Software Architecture and Functional Domain Modelling
This autumn, we read Domain Driven Design Made Functional in our book club. The book was quite inspiring and served as the spark for this blog post.
We also organized a virtual meetup on the topic in the Tech Excellence Finland meetup group.
What is Functional Domain Modelling?
It is Domain Driven Design (DDD) applied to the Functional Programming (FP) paradigm.
Both DDD and FP are extensive topics that one could write several books about.
If one were to try to summarize them briefly: in DDD, the software’s code and structure map directly to the business model and its terminology. In FP, we program using functions and avoid side effects (e.g., all I/O and exceptions). If these concepts feel unfamiliar at this point, I recommend checking what Wikipedia says about them.
We begin by looking at software architectures because they provide a good introduction to the topic.
Architectures
What is software architecture? It is, in a way, the blueprint of the software. All software has one, whether it was consciously created or emerged unconsciously. That is, what parts the software is built from and how those parts relate to each other.
A very typical and traditional software architecture is the so-called layered architecture.
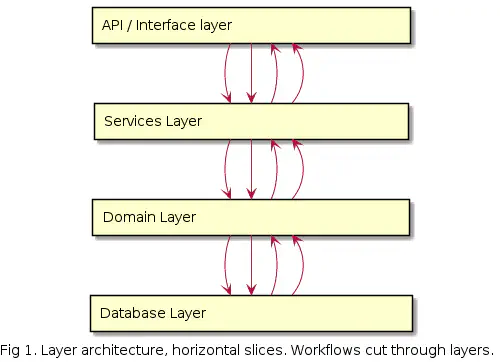
From the image, we can see the different layers of software architecture and how workflows (cf. use cases) cut through the layers.
In this architecture, you typically see all REST controllers side by side, and often one controller covers multiple use cases. If object-oriented programming has been used, classes may typically contain many methods and, correspondingly, many dependencies. Use cases cut through the layers and are not necessarily clearly separated from each other.
The number and names of the layers vary depending on who you ask, but the principle holds. Among these, the Domain Layer is intentionally included because it is meant to contain all business logic, i.e., the DDD part.
The situation can be improved by separating use cases by moving to a vertical slice architecture. In practice, this is still a layered architecture but designed so that each use case is isolated as much as possible from other use cases.
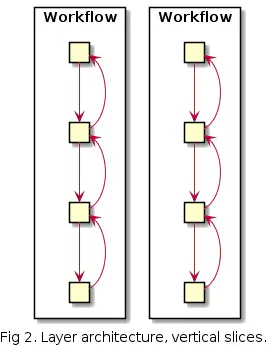
Now the use cases are clearly separated from each other.
If we draw a single use case as a sequence diagram, it looks like this:
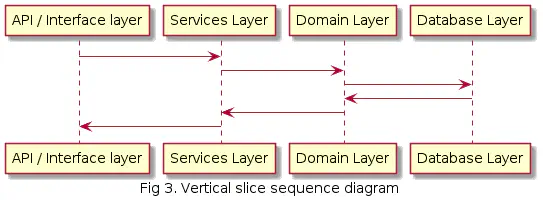
And if we stretch the sequence diagram out:
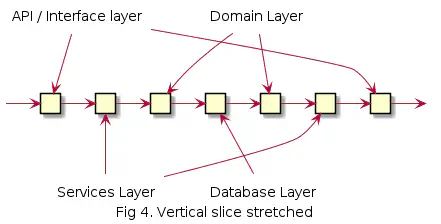
The images clearly show how the Domain layer is dependent on the Database Layer. This is problematic for testing, among other things.
The problem can be fixed by moving to a domain-centric architecture:
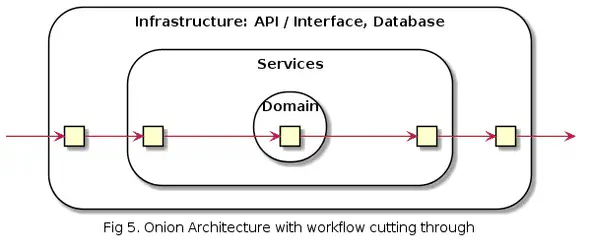
This is an example of Onion Architecture. The image shows a workflow cutting through the layers, but the Domain layer is now in the center, meaning it has no dependency on, for example, the database.
There are also numerous other domain-centric software architecture brands available:
What all of these have in common is that the domain is at the center and everything else is around it.
Domain
The domain is intended to contain all business logic that exists in the application. This is the layer where DDD effectively resides.
For example, data received in a REST API call is validated only in the domain layer and not in the REST controller, even though many REST frameworks would allow this fairly easily at some level. Similarly, the domain layer knows, for example, how long a person’s first name can be. Unfortunately, it is common to see these types of constraints implemented either in the database schema or using an ORM library where validation is left.
The domain should be free of all dependencies. Also from all utility libraries and frameworks. If there are any dependencies, their stability, maturity, and expected lifecycle should ideally approach those of the programming language used (see Stable Dependency Principle (SDP)). The idea is that frameworks (e.g., Spring Boot, Micronaut, Quarkus) are only small implementation-level details that are easily replaceable.
If the thought of performing all validations in the domain without framework helpers seems strange, it is thanks to this that the domain can easily serve different user interfaces/protocols, e.g., web, native applications, embedded systems, REST, Protocol Buffers, etc.
Also, the thought that, for example, Spring Boot would be just a small implementation-level detail that is easily replaceable might cause some to cringe.
Boundaries
The domain (bounded context) should be isolated from the rest of the code. This is done using DTOs.
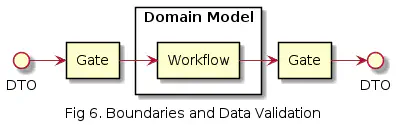
In the image above, the Gate component transforms the incoming DTO object into the domain’s own format. And similarly when writing out. In the image, the domain boundary could also include the DTOs themselves, depending on how the domain is intended to be isolated.
What is essential is that the domain’s data models are kept separate from the data models used in, for example, REST interfaces. Often, the data model for the domain and REST may be 1:1, at least in new applications, which can feel redundant if you have to convert to a completely identical data model. However, the purpose is to allow, for example, the REST interface’s data model to evolve independently of the domain model.
In DDD, there is also talk of Context Mapping, which is also related to this topic. These include Shared Kernel, Customer/Supplier, and Conformist. Briefly, these are about how bounded contexts are separated from each other. Perfect isolation is not always appropriate, and contexts can, for example, share a part of the domain.
I/O
If the Domain layer does not contain any dependencies and we should still use functional programming, which should avoid side effects like writing to or reading from a disk, then how and where do database operations happen?
The short answer is that they are modeled in the Domain layer, for example, using interfaces or functions that do not take a stand on the implementation. Another way to think about it is that, for example, the database depends on the domain and knows how to convert the domain model into database rows. We will return to this topic in more detail later.
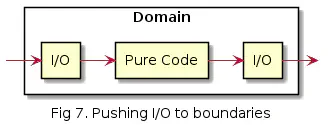
However, it is good to place I/O operations such that the pure code (which is completely free of side effects) remains as intact and consistent as possible. In this case, I/O would remain on the edges of the domain:
And if it is not possible to keep I/O purely on the edges, the next best option is to isolate it:
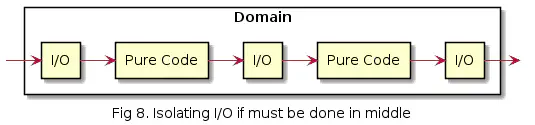
This makes the code, among other things, easier to test.
Workflows & Domain Driven Design
Below is an illustration of an event pipeline in DDD:

An Event triggers a Command which starts a Workflow, resulting in 0..n Events.
The difference between an Event and a Command is that an Event is an irreversible fact—i.e., something has happened. A Command, on the other hand, is something that can fail.
Software built this way is often easily scalable and modifiable. This is an event-based architecture.
A bounded context can contain several workflows (cf. use cases) that take a Command as input and produce Events as output.
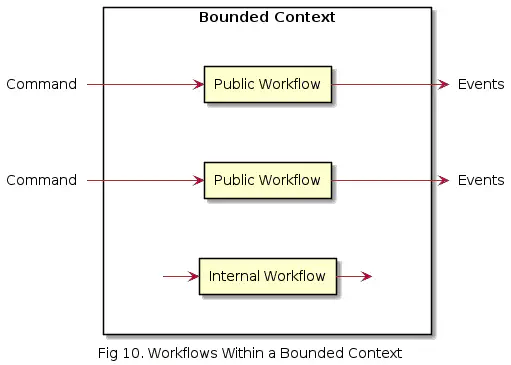
And the workflows themselves can consist of several smaller subflows.
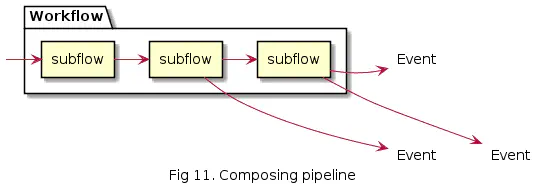
From a functional programming perspective, flows are functions that can be composed of smaller flows.
Functional Programming and I/O
We haven’t discussed functional programming in much detail because it is fundamentally very simple: programming using functions and avoiding side effects.
But regarding side effects—most often I/O—it is good to clarify this a bit.
There are roughly two schools of thought on this. The first school advocates for pure functional programming, where code is genuinely free of side effects and they are modeled using, for example, the IO monad. The second school is not nearly as purist and contents itself with stating that if something truly exceptional happens, the application can throw an exception. Examples of these could be a lost database connection or running out of disk space. In this post, we are in the shoes of the latter school and are satisfied with stating that throwing exceptions in exceptional situations is OK.
In principle, a third option could be to try to document in the code, one way or another, that some side effects might occur. In the Java world, where checked exceptions are used, one could try to describe this by using, for example, IOException in the method signature. In practice, this is not worth the effort if the intention is only to document the effects.
Very close to the third option is also Railway oriented programming, but it should not be done on very light grounds (see Against Railway-Oriented Programming).
Example
At this stage, we move on to a concrete example of functional domain modeling.
The example is borrowing a book. Below is the Kotlin code where this is implemented.
We have UserId and BookId, which can be either Valid or Unvalidated.
The command is BorrowBook, which contains the bookId and userId.
Additionally, we have BorrowResult, under which all possible outgoing domain Events can be found: Borrowed, BookNotFound, UserNotFound, and BookNotCurrentlyAvailable.
Operations requiring I/O are ValidateUserId, ValidateBookId, and MarkBookBorrowed. These either simply succeed or return null. The interpretation of the null value is left to the user.
Next is BorrowBookFlow, which takes in dependencies and the Command and returns an Event. This encapsulates the design of the entire flow.
Finally, there is borrowBookFlow, which implements the entire flow. This is perhaps the least interesting of these from a design perspective.
Let’s look at the ValidateUserId function, for example. It takes an UnvalidatedUserId as an argument and returns a ValidUserId or null. In principle, this could be replaced with an isExistingUserId type function that would return a boolean value, but here the intention was specifically to emphasize the semantics of the business logic and strive to keep the code in line with Domain Driven Design principles. The current version documents itself well and corresponds to the real intent: the ID is either valid or not. It does not take a stand on the domain event that will be returned.
However, it is good to remember that all business logic must be in the domain layer, so care must be taken not to accidentally add any extra logic to the functions that implement these.
If we next look at the MarkBookBorrowed function. What makes it interesting is that it directly returns the domain event Borrowed (or null). This choice could be criticized. If the domain event needs to be changed, all implementations would also have to be changed. This kind of choice might be justified for practical reasons if, for example, we know that no other implementations are currently in sight, the data model is extremely simple, etc. In any case, there must be a separate DTO for Borrowed in the externally visible interface (e.g., REST).
From Object Oriented to Functional
The previous example might look a bit unusual if you’re not used to Kotlin’s syntax and functional approach, so let’s take a short OO section before the summary.
In the traditional OO approach, the ValidateUserId function might be modeled like this:
There is nothing wrong with this per se. There is just more code, and the code is perhaps a bit more self-documenting. On the other hand, the code could be said to repeat itself perhaps even too much.
Of course, object-oriented programming has its advantages, but the more one practices FP programming, the narrower the OO application areas become in general programming. Or at least that’s my personal experience.
Finally
Domain Driven Design and Functional Programming are a great combination.
But as with everything, this is just one way to do things. An experienced crafter knows how to see when FP+DDD is the right choice and when something else works better. My own view is that FP+DDD is at least a good starting point if the programming language used supports it.
Only by exposing oneself to different techniques, languages, and methods can one learn and become better.
We are Bytecraft Oy.
Welcome to join us if this text spoke to you and you want to grow as a professional among professionals: hello@bytecraft.fi.
This article is part of the broader software craftsmanship conversation at Bytecraft. For a comprehensive overview of the practices that make code evolvable and maintainable, see What Is Software Craftsmanship?




