
Meillä oli tänä syksynä kirjakerhossa kirjana Domain Driven Design Made Functional. Kirja oli varsin inspiroiva ja se myös antoi kimmokkeen tälle poustaukselle.
Järjestimme aiheesta myös virtuaalisen meetupin Tech Excellence Finlandin meetup ryhmässä.
Mitä on Functional Domain Modelling?
Kyseessä on Domain Driven Desing (DDD) sovellettuna Functional Programming (FP) paradigmaan.
Sekä DDD että FP ovat sen verran laajoja aiheita että niistä voisi kirjoittaa useamman kirjan.
Jos näitä pitäisi yrittää tiivistää lyhyesti niin DDD:ssä ohjelmiston koodi ja rakenne kuvautuvat suoraan liiketoimintamalliin sekä sen käsitteistöön. FP:ssä ohjelmoidaan käyttäen funktioita ja vältetään side-efektejä (esim kaikki I/O ja exceptionit). Jos tässä kohtaa käsitteet tuntuvat vierailta niin suosittelen tarkastamaan esim. mitä Wikipedia näistä sanoo.
Aloitamme tarkastelemalla ohjelmisto arkkitehtuureita koska nämä tarjoavat hyvän johdannon aiheeseen.
Arkkitehtuurit
Mikä on ohjelmistoarkkitehtuuri? Se on tavallaan ohjelmiston pohjapiirrustus. Kaikilla ohjelmistoilla sellainen on oli se tietoisesti luotu tai tiedostamatta syntynyt. Eli mistä osista ohjelmisto on kasattu ja miten osat liittyvät toisiinsa.
Hyvin tyypillinen ja perinteinen ohjelmistoarkkitehtuuri on ns. layered arkkitehtuuri.
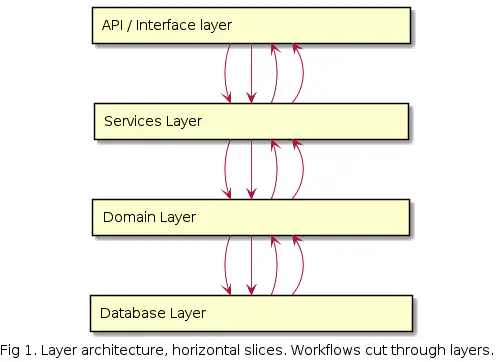
Kuvasta näemme ohjelmistoarkkitehtuurin eri kerrokset ja miten workflowt (vrt. käyttötapaukset) leikkaavat kerrosten läpi.
Tässä arkkitehtuurissa tyypillisesti näkee esimerkiksi kaikki REST controllerit rinnakkain ja usein yksi controller käsittää useamman käyttötapauksen. Jos käytössä on ollut olio-ohjelmointi niin tyypillisesti luokat saattavat sisältää paljon metodeita ja vastaavasti ne omaavat myös paljon riippuvuuksia. Käyttötapaukset leikkaavat kerrosten läpi eivätkä välttämättä ole selkeästi erillään toisistaan.
Kerrosten määrä ja nimet vaihtelevat riippuen keneltä kysyy mutta periaate pitää. Näistä Domain Layer on tässä tarkoituksella mukana koska sen on tarkoitus pitää sisällään kaikki liiketoimintalogiikka, eli DDD osuus.
Tilannetta voidaan parantaa eriyttämällä käyttötapaukset siirtymällä vertical slice arkkitehtuuriin. Käytännössä tämä on edelleen layered arkkitehtuuri mutta siten että jokainen käyttötapaus on pyritty eristämään mahdollisimman pitkälti muista käyttötapauksista.
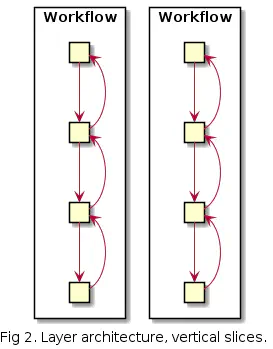
Nyt käyttötapaukset ovat selkeästi erillään toisistaan.
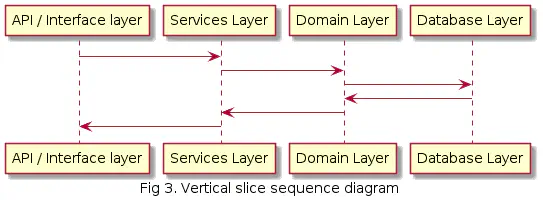
Jos piirrämme auki yksittäisen käyttötapauksen sekvenssi diagrammina niin se näyttää tältä:
Ja jos venytämme sekvenssi diagrammin auki:
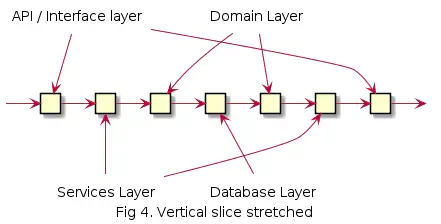
Kuvista näkyy hyvin kuinka Domain layer on riippuvainen Database Layeristä. Tämä on ongelmallista mm. testaamisen kannalta.
Ongelman voi korjata siirtymällä domain keskeiseen arkkitehtuuriin:
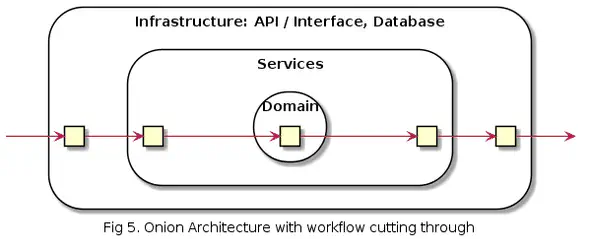
Tässä on esimerkkinä Onion Architecture. Kuvasta näkyy kun workflow leikkaa kerrosten läpi mutta Domain layer on nyt keskellä tarkoittaen että sillä ei ole riippuvuutta esim. tietokantaan.
Tarjolla on myös lukuisia muita domain keskeisiä ohjelmistoarkkitehtuuri brändejä:
Kaikille näille yhteistä on että domain on keskiössä ja kaikki muu ympärillä.
Domain
Domainin on tarkoitus sisältää kaikki liiketoiminta logiikka joka sovelluksessa on. Tämä on se layer jonne DDD efektiivisesti sijoittuu.
Esimerkiksi REST apista kutsussa sisään saatu data validoidaan vasta domain layerillä eikä REST controllerissa vaikka useat REST frameworkit mahdollistaisivatkin tämän melko helposti ainakin jollain tasolla. Ja vastaavasti domain layer tietää esim. kuinka pitkä henkilön etunimi voi olla. Valitettavasti usein näkee että tämän tyyppiset rajoitukset on tehty joko tietokanta schemaan tai käytetään ORM kirjastoa jonne validaatio on jätetty.
Domainin tulisi olla vapaa kaikista riippuvuuksista. Myös kaikista apu-kirjastoista ja frameworkeistä. Jos jotain riippuvuuksia on niin niiden vakauden, kypsyyden ja odotetun elinkaaren olisi hyvä lähennellä käytetyn ohjelmointikielen vastaavia attribuutteja (ks. Stable Dependency Principle (SDP)). Ideana on että frameworkit (esim. Spring Boot, Micronaut, Quarkus) ovat vain pieniä implementaatio tason yksityiskohtia jotka ovat helposti vaihdettavissa.
Jos ajatus kaikkien validaatioiden tekemisestä domainissa ilman frameworkin apuvälineitä on outo, niin sen ansioista domain voi palvella helposti eri käyttöliittymiä/protokollia, esim. web, natiivit sovellukset, sulautettu järjestelmät, REST, Protocol Buffers, jne.
Myös ajatus siitä että esim. Spring Boot olisi vain pieni implementaatio tason yksityiskohta joka on helposti korvattavissa saattaa aiheuttaa joillekin kramppeja.
Boundaries
Domain (bounded context) tulisi eristää muusta koodista. Tämä tapahtuu DTO avulla.
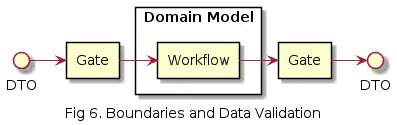
Yllä olevassa kuvassa Gate komponentti muuttaa sisään tulevan DTO objektin domainin omaan muotoon. Ja vastaavasti ulos kirjoittaessa. Kuvassa domain boundary voisi myös käsittää itse DTO:t riippuen miten domain on haluttu eristää.
Oleellista on että domainin tietomallit pidetään erillään esim. REST rajapinnoissa käytettävistä tietomalleista. Usein domainin ja RESTin tietomalli saattaa olla 1:1 ainakin uusissa sovelluksissa mikä voi tuntua turhalta jos joutuu konvertoimaan täysin identtiseen tietomalliin. Tarkoitus on kuitenkin mahdollistaa että esim. REST rajapinnan tietomalli voi elää itsenäisesti riippumatta domain mallista.
DDD:ssä puhutaan myös Context Mapping:sta mikä liittyy myös tähän aiheeseen. Näitä on mm. Shared Kernel, Customer/Supplier ja Conformist. Lyhyesti näissä on kyse siitä miten bounded contextit ovat erillään toisistaan. Läheskään aina täydellinen eristys ei ole tarkoituksenmukaista ja contextit voivat esim. jakaa osan domainista.
I/O
Jos Domain layer ei sisällä mitään riippuvuuksia ja pitäisi vielä käyttää funktionaalista ohjelmointia jossa tulisi välttää side-efektejä kuten levylle kirjoittaminen tai sieltä lukeminen niin miten ja missä tietokantaoperaatiot tapahtuvat?
Lyhyt vastaus on että ne on mallinnettu Domain layerissä esimerkiksi käyttäen rajapintoja (interface) tai funktiota jotka eivät ota kantaa implementaatioon. Toinen tapa ajatella on että esim tietokanta riippuu domainista ja tietää miten domain malli muunnetaan tietokanta riveiksi. Palaamme tähän tähän aiheeseen myöhemmin tarkemmin.
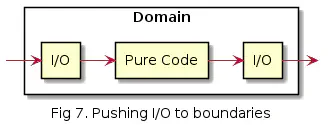
I/O operaatiot on kuitenkin hyvä sijoittaa siten että puhdas koodi (joka on täysin vapaa side-efekteistä) pysyy mahdollisimman eheänä ja yhtenäisenä. Tällöin I/O jäisi domainin reunoille:
Ja jos I/O:ta ei ole mahdollista pitää puhtaasti reunoilla niin toiseksi paras vaihtoehto on eristää se:
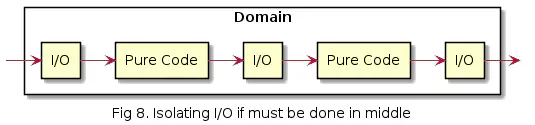
Tämä tekee koodista mm. helpommin testattavaa.
Workflows & Domain Driven Design
Alla on havainnollistettu event pipeline DDD:stä

Jokin Event laukaisee Commandin joka käynnistää Workflown jonka tuloksena on 0..n Eventtiä.
Eventin ja Commandin ero on siinä että Event on peruuttamaton fakta. ts. jotain on tapahtunut. Command on taas jotain mikä voi epäonnistua.
Tällä tavoin rakennetut ohjelmistot ovat usein helposti skaalattavissa ja muokattavissa. Kyseessä on event pohjainen arkkitehtuuri.
Bounded context voi sisältää useita workflowta (vrt. use case) jotka saavat syötteenä Commandin ja tuottavat ulos Eventtejä
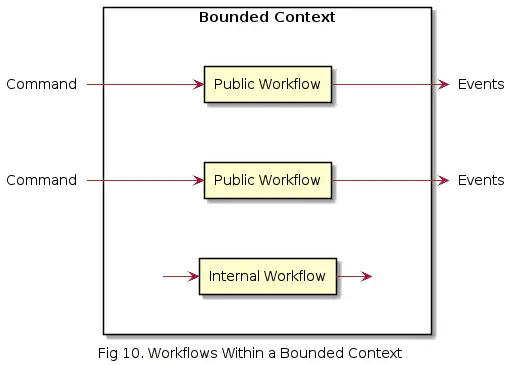
Ja workflowt itsessään voivat koostua useasta pienemmästä subflowsta.
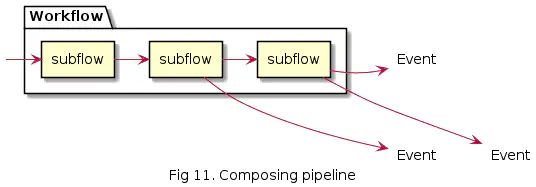
Funktionaalista ohjelmointia ajatellen flowt ovat funktioita jotka taas voivat olla ovat koostettu pienemmistä flowsta.
Funktionaalinen ohjelmointi ja I/O
Funktionaalista ohjelmointia emme ole juuri erityisemmin käsitelleet koska se on periaatteessa hyvin yksinkertaista: ohjelmoidaan käyttäen funktioita sekä vältetään side-efektejä.
Mutta side-efektien, eli useimmiten I/O:n osalta, tätä on hyvä avata hiukan.
Tähän on olemassa suurin piirtein kaksi koulukuntaa. Ensimmäinen koulukunta liputtaa puhtaan funktionaalisen ohjelmoinnin puolesta jossa koodi on aidosti vapaa side-efekteistä ja ne on mallinnettu käyttäen esim. IO monadia. Toinen koulukunta ei ole läheskään näin puristinen ja tyytyy toteamaan että jos jotain oikeasti poikkeuksellista tapahtuu niin sovellus voi heittää poikkeuksen. Näistä voisi olla esimerkkeinä tietokanta yhteyden katkeaminen ja levytilan loppuminen. Tässä kirjoituksessa olemme jälkimmäisen koulukunnan saappaissa ja tyydymme toteamaan että poikkeusten heittäminen poikkeuksellisissa tilanteissa on OK.
Periaatteessa kolmas vaihtoehto voisi olla yrittää dokumentoida koodiin tavalla tai toisella että jotain side-efektejä saattaa tapahtua. Java maailmassa jossa käytössä on checked exceptionit joilla asiaa voisi yrittää kuvata käyttämällä esim IOExceptiniä metodien signaturessa. Käytännössä tämä ei maksa vaivaa jos tarkoitus on vain dokumentoida efektit.
Hyvin lähellä kolmatta vaihtoehtoa on myös Railway oriented programming mutta sitä ei kannata tehdä kovin kevyin perustein (ks. Against Railway-Oriented Programming).
Esimerkki
Tässä vaiheessa siirrymme konkreettiseen funktionaalisen domain mallinnuksen esimerkkiin.
Esimerkkinä on kirjan lainaaminen. Alla on Kotlin koodi jossa tämä on implementoitu.
Meillä on UserId sekä BookId jotka voivat olla joko Valid tai Unvalidated.
Commandina on BorrowBook joka pitää sisällään bookIdn sekä userIdn.
Lisäksi meillä on BorrowResult jonka alta löytyy kaikki mahdolliset lähtevät domain Eventit: Borrowed, BookNotFound, UserNotFound ja BookNotCurrentlyAvailable.
I/O:ta vaativat operaatiot ovat ValidateUserId, ValidateBookId sekä MarkBookBorrowed. Nämä joko yksinkertaisesti onnistuvat tai palauttavat nullin. null arvon tulkinta jää käyttäjän vastuulle.
Seuraavaksi on BorrowBookFlow joka ottaa riippuvuudet sisään sekä Commandin ja palauttaa Eventin. Tähän kiteytyy koko flown design.
Viimeisenä on borrowBookFlow joka implementoi koko flown. Tämä on näistä ehkä vähiten kiinnostava design mielessä.
Tarkastellaan vaikka ValidateUserId funktiota. Se ottaa argumenttina UnvalidatedUserIdn ja palauttaa ValidUserIdn tai nullin. Periaatteessa tämän voisi korvata isExistingUserId tyyppisellä funktiolla joka palauttaisi boolean arvon mutta tässä on nimenomaan haluttu korostaa liiketoimintalogiikan semantiikkaa ja pyrkiä pitämään koodi Domain Driven Design prinsiippien mukaisena. Nykyinen versio dokumentoi itsensä hyvin ja vastaa todellista aietta: id on joko valid tai ei. Tässä ei oteta kantaa domain eventtiin joka tullaan palauttamaan.
On hyvä kuitenkin muistaa että kaikki liiketoimintalogiikka tulee olla domain layerissä jolloin tulee varoa ettei vahingossa tule lisänneeksi mitään ylimääräistä logiikkaa funktioihin jotka implementoivat nämä.
Jos seuraavaksi tarkastelemme MarkBookBorrowed funktiota. Mielenkiintoisen siitä tekee se että se palauttaa suoraan domain eventin Borrowed (tai nullin). Tätä valintaa voisi kritisoida. Jos domain eventtiä joudutaan muuttamaan niin kaikki implementaatiot pitäisi käydä myös muuttamassa. Tämän kaltainen valinta saattaa olla perusteltua käytännön syistä jos esim. tiedämme että muita implementaatioita ei ole juuri näkyvissä, tietomalli on äärimmäisen yksinkertainen tms. Ulospäin näkyvässä rajapinnassa (esim. REST) Borrowedlle tulee joka tapauksessa olla oma DTO:nsa.
From Object Oriented to Functional
Edellinen esimerkki saattaa näyttää hiukan erikoiselta jos ei ole tottunut Kotlinin syntaksiin ja funktionaaliseen lähestymistapaan joten otetaan vielä lyhyt OO osuus ennen yhteenvetoa.
Perinteisessä OO lähestymistavassa ValidateUserId funktio saattaisi olla mallinnettu näin
Tässä ei sinänsä ole mitään vikaa. Koodia vain on enemmän ja koodi on ehkä aavistuksen verran enemmän itseään dokumentoivaa. Toisaalta koodin voidaan todeta toistavan itseään ehkä liikaakin.
Toki olio-ohjelmoinnissa on etunsa mutta mitä enemmän FP ohjelmointia harrastaa niin sitä kapeammiksi OO sovellutusalueet alkavat käydä yleisessä ohjelmoinnissa. Tai tämä on ainakin oma henkilökohtainen kokemukseni.
Lopuksi
Domain Driven Design ja Functional Programming ovat loistava yhdistelmä.
Mutta kuten kaikessa, tämäkin on vain yksi tapa tehdä asioita. Kokenut craftaaja osaa nähdä milloin FP+DDD on oikea valinta ja milloin jokin muu toimii paremmin. Oma näkemykseni on että FP+DDD on ainakin hyvä lähtökohta jos käytettävä ohjelmointikieli sitä tukee.
Ainoastaan altistamalla itsensä erilaisille tekniikoille, kielille, menetelmille voi oppia ja tulla paremmaksi.
Me olemme Bytecraft Oy.
Tervetuloa joukkoomme jos teksti puhutteli ja haluat kasvaa ammattilaisena ammattilaisten joukossa: hello@bytecraft.fi.




